




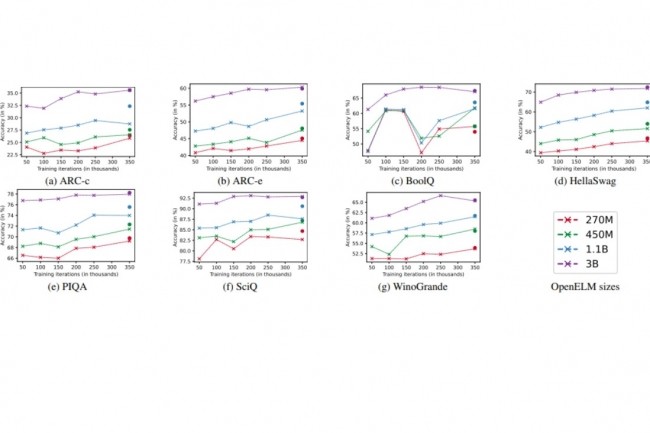
En décembre dernier, Apple avait révélé son LLM Ferret. Aujourd’hui, l’entreprise fait part d’un nouveau modèle de langage de petite taille, également en open source, qu’elle a nommé OpenELM. On peut le trouver en quatre différentes dimensions, allant de 270 millions à un peu plus de 3 milliards de paramètres. La version 1.1B de ce modèle serait un peu plus efficace que l’OLMo, même si elle prendrait un peu plus de temps à fonctionner.
Les LLM, ou modèles de langage à grande échelle, sont constamment à l’honneur dans l’actualité. Ils sont souvent associés aux SLM, qui sont des versions plus petites de ces modèles de langage. Récemment, Microsoft a dévoilé Phi-3 Mini, capable de fonctionner sur des smartphones, ainsi qu’Orca-Math en mars. Désormais, c’est Apple qui fait son entrée sur ce marché en introduisant OpenELM. Ce n’est pas la première fois qu’Apple s’engage dans le domaine des modèles de langage. En décembre de l’année précédente, en collaboration avec l’Université de Cornell, la société a lancé un LLM open source nommé Ferret, destiné uniquement à la recherche. Bien que Ferret puisse atteindre jusqu’à 13 milliards de paramètres, OpenELM ne se situe pas dans la même catégorie avec des versions plus petites : 270 M, 450 M, 1,08 B et 3,04 B.
Apple explique dans un document de recherche qu’OpenELM utilise une stratégie de mise à l’échelle par couche (layer-wise scaling) pour attribuer efficacement les paramètres au sein de chaque couche du modèle de transformateur, améliorant ainsi la précision. Pour appuyer cette affirmation, Apple indique que OpenELM 1.1 B offre une précision supérieure de 2,36% par rapport à OLMo, tout en nécessitant deux fois moins de paramètres et en demandant deux fois moins de tokens de pré-entraînement. OLMo a été développé par l’Ai2, une organisation à but non lucratif fondée en 2014 par Paul Allen, co-fondateur de Microsoft avec Bill Gates. Apple ne compare pas seulement OpenELM à OLMo, mais également à d’autres modèles tels que OPT (Meta AI), MobiLlama et TinyLlama (dérivés open source de Llama de Meta), Pythia (EleutherAI), OpenLM (Apache LangChain) et Cerebras-GPT (Cerebras).
Des efforts pour accélérer l’exécution
La performance d’OpenELM par rapport à ses concurrents semble cependant avoir un inconvénient pour le moment : « Malgré une plus grande précision d’OpenELM pour un nombre de paramètres similaire, nous constatons qu’il est plus lent qu’OLMo », admet Apple. Bien que l’objectif principal de l’étude d’Apple soit davantage centré sur la reproductibilité que sur la performance de l’inférence, une analyse a été réalisée pour comprendre ce retard.
À l’avenir, Apple envisage de « chercher des stratégies d’optimisation pour améliorer l’efficacité de l’inférence d’OpenELM, ce qui passera par une meilleure mise en œuvre de RMS Norm (Root Mean Square Layer Normalization) ». Cette technique permet de réguler la somme des entrées d’un neurone dans une couche en fonction de la moyenne quadratique (RMS).


0 commentaires